软件工程实践系列文章,
会着重讲述实际的工程项目中是如何协作开发软件的。
本文主要介绍了 django/python 系列的工具链。
outline
本文包括以下内容:
- outline
- django: 一个搭建后端服务的工具箱。
- framework: django vs flask/tornado/spring/laravel
- restful: django/restframework/swagger
- worker: django/uwsgi/gevent/celery/channels
- database: django/mysql/sqlite/migrations
- python: 一门依赖开发者的语言。
- developing: gitlab/pipenv/docker
- quality: unittest/pytest/flake8/pylint/yapf
- deploy: fabric/aws/nginx
- conclusion
django
django 是一个大名鼎鼎的后端开发框架,
它自己的口号是 the web framework for perfectionists with deadlines.
在我用 django 开发的这几年来,
我觉得它是一个逻辑上自洽,
并且为了逻辑自洽甚至舍弃了一部分功能的框架。
framework
search google for
django vs
讲框架避免不了的是同行竞争,
比如到网上搜一下 django vs ... 就有一大堆搜索结果。
其实框架之间的比较是很难的,
每种框架都有自己适合的业务场景。

xkcd-927: standards
django 最大的特点就是 Model 是一等公民。
在 django 中的所有的操作都会跟 Model 相关,
比如它提供了自带的强大 ORM,
也有一系列挂载在 Model 上的校验等。
个人感觉在项目的业务需求达到了某种程度的多样化以后,
基础框架用什么并不重要,
适合开发团队才是最重要的。
鉴于本文的标题是 django,
所以我们只讲 django。
restful
我参与的项目基本都是前后端分离的项目,
后端提供的接口都是用 djangorestframework 写的。
虽然像 HATEOAS 这样的高级属性还没用到,
但接口是遵循 restful 风格的,
比如像用 http method+status 表达语义,
对资源的定义等。
接口文档我们选用了 drf-yasg 来生成符合 swagger 规范的文档。
曾经我们也试过 django-rest-swagger 这个库,不过……
another help-wanted project…
使用现成框架的好处是语言表达力极强,
最终我们实现一个“解密微信提供的手机号”接口的伪业务代码大概如下:
class WeChatVS(BaseVS):
@with_response(empty=True)
@with_request(DecryptionSiri)
@action(methods=['post'], detail=True, url_path='decryption/phone')
def decrypt_wechat_phone(self, request, uid):
""" 解密并修改用户的手机号
- https://developers.weixin.qq.com/miniprogram/dev/framework/open-ability/getPhoneNumber.html
"""
self.check_account_request(request, uid)
openid, encrypted_data, initial_vector = self.request_data
phone = WeChatManager(openid).decrypt_safely(encrypted_data, initial_vector)
# TODO(ldsink): 找产品问一下外国手机号怎么处理
hutils.check_error(not hutils.is_chinese_phone(phone), 'o(╥﹏╥)o 目前只支持国内的手机号')
self.account.modify(phone=phone)
return self.empty_response()
这样的十行代码包含了文档、外链、错误检查、写库,
让写业务代码本身也有种施法的快感。
worker
最开始服务器上我们跑的是 django+uwsgi 的普通模式,
用 wrk 去压一个小接口,
测试环境 4G 内存的机器 QPS 只有 40 左右。
后来加上了 gevent, monkey patch 一下,改到了协程模式
同样的接口同样的机器 QPS 上升到了大概 600。
调优一下效果会更好。
(需要更高性能的业务可能就根本不用 python 了 Orz)
celery 充当了我们的定时任务+异步任务框架,
我们也拆分了 读写密集型/计算密集型 的两类队列以处理不同的事情。
对于业务中的即时通知部分,
我们用了 channels 库来实现 web socket 的功能。
对于这些大型的框架,其实我们选择余地并不大。
比如虽然 django 开发者有说在 3.0 会考虑大幅度重写异步调用,
channels 项目会逐渐弃坑……
但毕竟 perfectionists with deadlines.
不能说人家功能不完美,我们就不干活了嘛…
database
我们用到的数据库也是 mysql/mongo/redis 这御三家,
所以就是每个选取对应的连接库就是了。
值得一提的是在单元测试里,
我们用 sqlite(in-memory) 替代了 mysql 数据库。
sqlite 里缺失了 mysql 的函数的问题,
也可以用 connection.create_function 的方法来规避掉。
在上线时,还有一个很好玩的东西是 database migration,
这个基本上跟“给行驶中的火车换轮子”一样刺激。
详细的细节以后会专门开篇文章讲一下(挖坑预警),
从结果上来说我们做到的是利用 Django Migration 做到数据库结构变更全兼容。
python
上面一小节中,我们基本上是走马观花地过完了 django 相关的三方库。
到了真正用 python 开发的时候,
我们遇到的更多的是框架之外的奇遇。
每门语言都有自己的味道。
我很喜欢 python 的一点是:
这门语言有着非常强的表达张力。
就像上面举的那段典型业务代码一样,
在实际的开发中,
python 是能完美表达开发者心中所想的。
但假如开发者自己都没想清楚自己要写啥,
这就有点不妙了。
所以我们有一系列的开发工具来保持清醒。

强制清醒.jpg
quality
除了开发流程上的类似要求,
我们对代码本身也执行了类似的严格要求:
- 单元测试覆盖率必须得在 96% 以上 (unittest/pytest/coverage)
- 代码的逗号、换行、引号的使用都必须符合规范 (flake8)
- 代码强制经过 linter 检验,禁止多种黑魔法 (pylint)
- 代码的各个模块之间必须符合特定的拓扑顺序 (pylint-topology)
- 代码风格(如字典的复制、长列表、换行与空行)强制统一 (yapf)
其中单元测试覆盖率必须得在 96% 以上值得被单独拎出来表扬一下。
业务代码的 96% 的覆盖率是什么概念呢?
这意味着代码里只有那种真正的边缘情况是没被测到的。
(比如为了兼容微信 SYSTEM ERROR -1000 写的代码)
为了达到了这么高的覆盖率,
我们也专门强化过单元测试的表达力,
比如一段测试创建用户接口的伪代码可能如下:
def test_create_account(self):
""" 测试创建用户 """
with self.assert_model_increase(Account, delta=1):
response = self.client.post(self.account_url(), {'username': 'hulucc'})
self.ok(response, username='hulucc', tags__length=0)
with self.assert_model_increase(Account, delta=0):
response = self.client.post(self.account_url(), {'username': 'hulucc'})
self.bad_request(response, message=AccountErrors.DUPLICATE.value)
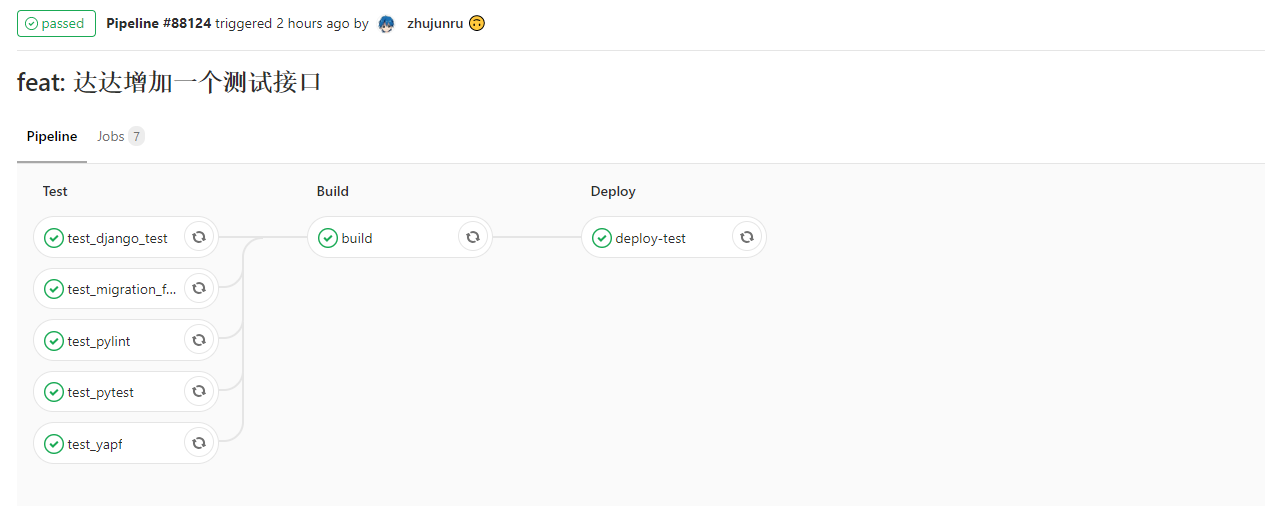
所有这些限制都在 CI 中检查了,不通过的话是不让 merge into master 的
developing
我们的合作方式是用 gitlab 作为代码托管平台。
为了团队的开发效率,
我们还自己写了个小机器人来处理各种如分支合并、有效性检查、贴标签之类的杂活。
gitlab ci 不仅被用来做开发阶段的质量保证,
最终我们的构建上线也走的是 gitlab ci (以前我们用的是 jenkins)
对于 python 的依赖管理,
我们用的是 pipenv,pip list 一下大概有了 181 个库。
(关于 pipenv 的介绍可以参见《Python 依赖管理的未来 - ldsink》)
也因为我们线上用的是 docker,
所以不想装依赖的也可以直接用 docker 的环境开发。
deploy
部署这一块我们暂时还没上 k8s,
目前走的是 gitlab ci 中调用 fabric + aws(boto3) 直接操作裸 docker 的方式。
aws 的负载均衡器提供了基础的流量切换服务,
我们也是借用了现成的服务达到灰度发布、无缝发布的效果。
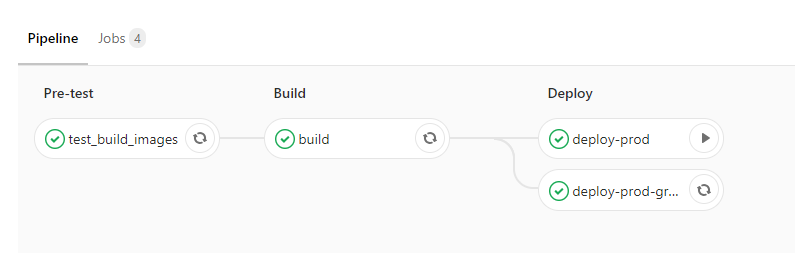
用 GitLab CI 部署的步骤图
conclusion
至此,本文介绍了一遍我们在 Python 业务后端的实践。
对于高可用、容器化、数据库等屠龙技,
业界其实有非常多的探讨,
大家也很容易找到现成的文章。
但具体到业务后端的工程化实践,
能借鉴的大型项目并不多。
我读过的也只有两年前的 reddit 代码跟 sentry 这个 django 项目符合要求了。
总的来说,我们用 django 在开发中遵循的约定跟共识有这些:
- 做正确的事情。
- 比如我们在讨论过后,一致觉得“线性的 Commit 历史是最干净的”,从当天开始我们的 Commit 历史就是干净的线性历史了。
- 自动化一切能自动化的工作。
- 用 swagger 自动化生成文档,用 gitlab ci 自动化质量保证。
- 尽可能使用最新的特性,让代码时刻保持崭新。
- 我们每隔一阵就会把所有依赖升到最新的稳定版。
- 不过因为这个我们也踩了不少坑。
- 不少时候三方库会引入全新的用法,动辄改动 100+ 的文件数。
- 这个时候就到了 Vim Macro 展现魔法的时候了。
假如你也在用 Django 作为后端框架的话,
不防尝试一下上面提到的各类工具,
绝对物超所值噢 :)
子岳叔,线性的 Commit 历史是指git中rebase这个魔法吗