The software engineering practice series articles
will focus on describing how actual engineering projects collaboratively develop software.
This article mainly introduces the django/python series of toolchains.
outline
This article includes the following:
- outline
- django: a toolbox for building backend services.
- framework: django vs flask/tornado/spring/laravel
- restful: django/restframework/swagger
- worker: django/uwsgi/gevent/celery/channels
- database: django/mysql/sqlite/migrations
- python: a language that depends on the developer.
- developing: gitlab/pipenv/docker
- quality: unittest/pytest/flake8/pylint/yapf
- deploy: fabric/aws/nginx
- conclusion
django
django is a famous backend development framework,
its own slogan is the web framework for perfectionists with deadlines.
In the years I’ve used django for development,
I feel it’s a logically self-consistent framework,
and one that even sacrifices some features for logical self-consistency.
framework
search google for
django vs
Talking about frameworks unavoidably involves peer competition,
for example searching django vs ... online gets a pile of results.
Actually comparing frameworks is hard,
each framework has its own suitable business scenarios.

xkcd-927: standards
The biggest characteristic of django is Model is a first-class citizen.
All operations in django are related to Model,
for example it provides a powerful built-in ORM,
and a series of validations etc. mounted on Model.
Personally I feel after a project’s business requirements reach a certain level of diversity,
what foundational framework to use doesn’t matter,
suitability for the development team is what matters most.
Given this article’s title is django,
we’ll only talk about django.
restful
The projects I’ve been involved in are basically all frontend-backend separated,
the backend interfaces are all written with djangorestframework.
Although advanced attributes like HATEOAS haven’t been used,
the interfaces follow restful style,
like using http method+status to express semantics,
defining resources, etc.
For interface documentation we chose drf-yasg to generate docs conforming to swagger specification.
We also tried the library django-rest-swagger, but…
another help-wanted project…
The benefit of using ready-made frameworks is extremely strong language expressiveness,
ultimately when we implement a “decrypt WeChat-provided phone number” interface the pseudo business code looks roughly like this:
class WeChatVS(BaseVS):
@with_response(empty=True)
@with_request(DecryptionSiri)
@action(methods=['post'], detail=True, url_path='decryption/phone')
def decrypt_wechat_phone(self, request, uid):
""" Decrypt and modify user's phone number
- https://developers.weixin.qq.com/miniprogram/dev/framework/open-ability/getPhoneNumber.html
"""
self.check_account_request(request, uid)
openid, encrypted_data, initial_vector = self.request_data
phone = WeChatManager(openid).decrypt_safely(encrypted_data, initial_vector)
# TODO(ldsink): ask product how to handle foreign phone numbers
hutils.check_error(not hutils.is_chinese_phone(phone), 'o(╥﹏╥)o Currently only domestic phone numbers are supported')
self.account.modify(phone=phone)
return self.empty_response()
These 10 lines of code include documentation, external links, error checking, database writes,
making writing business code itself feel like casting a spell.
worker
Initially on the server we ran the ordinary django+uwsgi mode,
using wrk to stress a small interface,
test environment 4G memory machine QPS was only about 40.
Later adding gevent, monkey patching, switched to coroutine mode,
the same interface on the same machine QPS rose to about 600.
Tuning would have even better effects.
(Business needing higher performance probably just wouldn’t use python Orz)
celery serves as our scheduled task + async task framework,
we also split read-write-intensive / compute-intensive queues to handle different things.
For real-time notification parts in the business,
we used the channels library to implement web socket functionality.
For these big frameworks, our choice range is actually not large.
For example although django developers said they’d consider heavily rewriting async calls in 3.0,
the channels project will gradually be abandoned…
But after all perfectionists with deadlines.
We can’t say someone else’s features aren’t perfect, so we won’t do work…
database
The databases we use are also the standard mysql/mongo/redis trio,
so each just picks the corresponding connection library.
Worth mentioning is in unit tests,
we used sqlite(in-memory) to replace mysql database.
The problem of missing mysql functions in sqlite,
can also be avoided with connection.create_function.
At launch time, there’s another fun thing called database migration,
this is basically as thrilling as “changing wheels on a moving train.”
Specific details will be covered in a dedicated article later (pit warning),
result-wise we achieved using Django Migration to fully compatibly do database structure changes.
python
In the previous section, we basically gave a flying overview of django-related third-party libraries.
When actually developing with python,
what we encounter more are adventures outside the framework.
Every language has its own flavor.
What I love about python is:
this language has very strong expressive tension.
Like that typical business code example above,
in actual development,
python can perfectly express what the developer is thinking.
But if the developer themself hasn’t thought clearly about what they want to write,
that’s a bit unfortunate.
So we have a series of development tools to stay awake.

Forced awake.jpg
quality
Besides similar requirements on dev process,
we also execute similar strict requirements on the code itself:
- Unit test coverage must be above 96% (unittest/pytest/coverage)
- Code’s commas, line breaks, quotes usage must conform to specification (flake8)
- Code is forced through linter checks, multiple black magics forbidden (pylint)
- Each module of code must conform to specific topological order (pylint-topology)
- Code style (like dict copying, long lists, line breaks and blank lines) forcibly unified (yapf)
Among them unit test coverage must be above 96% is worth singling out for praise.
What’s the concept of 96% coverage for business code?
This means only those truly edge cases in the code aren’t tested.
(Like code written for compatibility with WeChat SYSTEM ERROR -1000)
To achieve such high coverage,
we also specially strengthened unit test expressiveness,
for example a piece of pseudo code testing create user interface might look like:
def test_create_account(self):
""" Test creating account """
with self.assert_model_increase(Account, delta=1):
response = self.client.post(self.account_url(), {'username': 'hulucc'})
self.ok(response, username='hulucc', tags__length=0)
with self.assert_model_increase(Account, delta=0):
response = self.client.post(self.account_url(), {'username': 'hulucc'})
self.bad_request(response, message=AccountErrors.DUPLICATE.value)
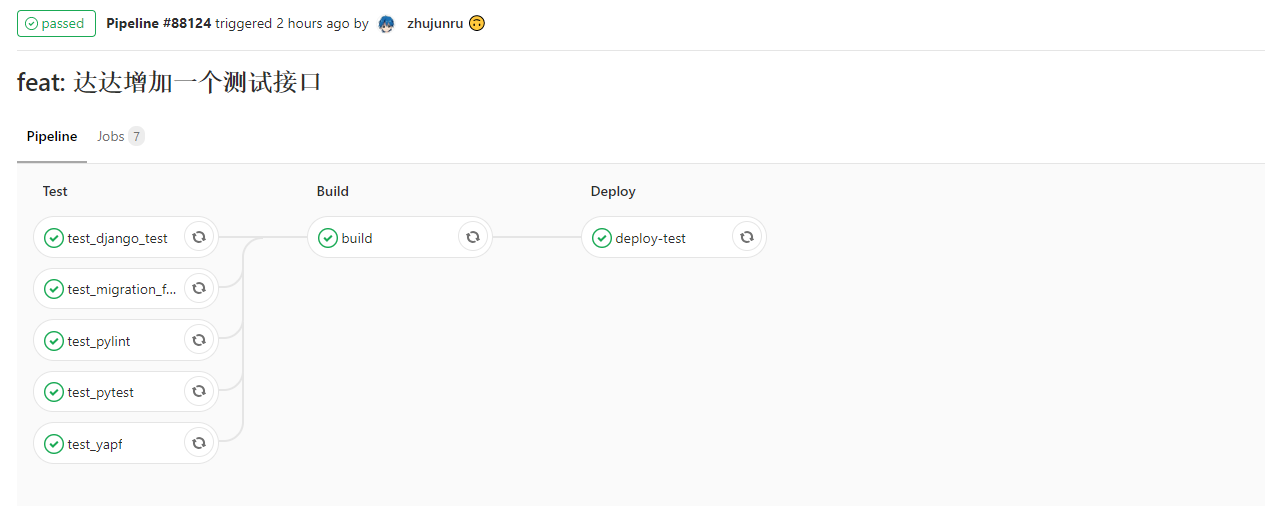
All these restrictions are checked in CI, if they don’t pass merging into master is forbidden
developing
Our cooperation method is using gitlab as code hosting platform.
For team development efficiency,
we also wrote a little bot ourselves to handle various chores like branch merging, validity checks, labeling.
gitlab ci is not only used for quality assurance in the development stage,
ultimately our build deployment also goes through gitlab ci (we used to use jenkins)
For python dependency management,
we use pipenv,pip list gives about 181 libraries.
(For pipenv introduction see 《The Future of Python Dependency Management - ldsink》)
And because what we use in production is docker,
those who don’t want to install dependencies can also develop directly using docker’s environment.
deploy
For deployment we haven’t moved to k8s yet,
currently using gitlab ci calling fabric + aws(boto3) to directly operate bare docker.
aws’s load balancer provides basic traffic switching service,
we also borrow this ready-made service to achieve gray release, seamless release effects.
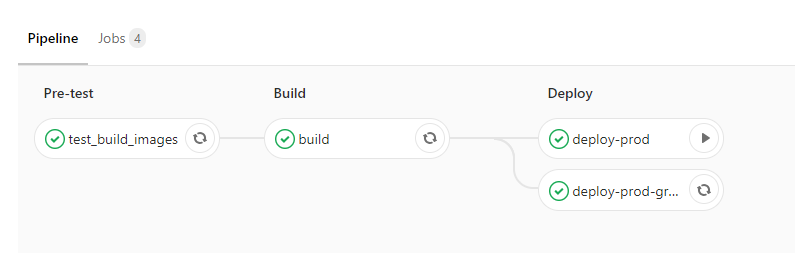
Deployment steps diagram using GitLab CI
conclusion
So far, this article has gone through our Python business backend practice.
For dragon-slaying skills like high availability, containerization, databases,
the industry has many discussions,
it’s also easy to find ready-made articles.
But specific to engineering practice for business backend,
there aren’t many large projects to learn from.
What I’ve read that meets the requirements is only Reddit’s code from two years ago and sentry the django project.
Overall, the conventions and consensus we follow in development with django are:
- Do the right thing.
- For example after discussion, we unanimously felt “linear Commit history is cleanest,” and from that day our Commit history was clean linear history.
- Automate everything that can be automated.
- Use swagger to automatically generate documentation, use gitlab ci to automate quality assurance.
- Use the latest features as much as possible, keeping code constantly fresh.
- We upgrade all dependencies to the latest stable version periodically.
- But we’ve also stepped on quite a few pits because of this.
- Often third-party libraries introduce completely new usages, changing 100+ files at a time.
- This is when Vim Macro shows its magic.
If you’re also using Django as your backend framework,
you might as well try the various tools mentioned above,
definitely worth more than you pay :)